SARA: the Socially Aware Robot Assistant
Overview
In this era of fears that Artificial Intelligence will destroy humanity, SARA is a Socially-Aware Robot Assistant, developed in Carnegie Mellon University’s ArticuLab. SARA interacts with people in a whole new way, personalizing the interaction and improving task performance by relying on information about the relationship between the human user and virtual assistant. Rather than taking the place of people, Sara is programmed to collaborate with her human users. Rather than ignoring the socio-emotional bonds that form the fabric of society, Sara depends on those bonds to improve her collaboration skills.
Specifically, Sara is always attending to two kinds of goals at the same time: a task goal (such as finding information for her human, helping her human to navigate a conference, or helping her human user to learn a new subject matter (such as linear algebra), and a social goal (ensuring that her interaction style is comfortable, engaging, and results in increased closeness and a better working relationship between human and agent over time).
Sara accomplishes this innovative approach to robot (or virtual agent) assistance using cutting edge socially-aware artificial intelligence, developed in the ArticuLab at Carnegie Mellon University Specifically, Sara is capable of detecting social behaviors in conversation, reasoning about how to respond to the intentions behind those particular behaviors, and generating appropriate social responses – as well as carrying out her task duties at the same time.
SARA was presented at the World Economic Forum (WEF) Annual Meeting in Davos (January 17-20, 2017), and World Economic Forum Annual Meeting of New Champions, in Tianjin, China (June 26-28, 2016).

“Hello, I’m SARA. I’m here to be your personal assistant.”
In terms of detection, Sara can recognize visual (body language, using algorithms we developed, as well as the capabilities of OpenFace), vocal (acoustic features of speech, such as intonation or loudness, also using algorithms we developed, as well as the capabilities of OpenSmile) and verbal (linguistic features of the interaction such as conversational strategies, using models and binary classifiers we developed) aspects of a human user’s speech. We leverage the power of recurrent neural networks (deep learning techniques) and L2 regularized logistic regression (a discriminative model in machine learning) with multimodal information from both the user and SARA (speech, acoustic voice quality, and the conversational strategies described above) to learn the fine-grained temporal relationships among these modalities, and their contextual information. Sara uses those sources of input to estimate the rapport between user and agent in real time. We call this social intention recognition, based on the classic natural language processing and AI process of “(task) intention recognition”
In terms of reasoning, Sara first carries out the classic kind of AI task reasoning needed to determine how best to fulfill the user’s goals. Then Sara carries out a brand new kind of reasoning — what we call “social reasoning” — to determine how to carry out the conversation (including language and body language) with the user so as to best accomplish both the task (information-seeking, teaching, calendar management, etc.) and social goals (managing rapport, etc.).
In terms of responding, the output of the social reasoner is sent to the Natural Language Generation module. That output of the social reasoner is suggestions (technically, those “suggestions” are the output of a spreading activation network where one conversational strategy is activated). Those social reasoner’s suggestions, such as
“the most effective way to increase rapport given the user’s last speech, and the current rapport level, and what Sara is trying to achieve at this point in the conversational strategy, would be in terms of a self-disclosure”
are sent to the Natural Language Generation module. The NLG module is responsible for generating language that fits the conversational strategy requested and is grammatically correct. For example, if self-disclosure is the optimal next strategy, the NLG might generate language for Sara as follows:
“I certainly find it difficult to remember information without noting it down. If you’re like me, you might take a screenshot so you remember this information.”
The NLG also generates appropriate body language for Sara – this body language includes hand gestures, shifts in eye gaze, smiles, head nods, etc., all with the goal of establishing and building a durable relationship with the user over time. Sara’s body was designed and animated by our talented animators, and implemented using the Virtual Human Toolkit.
This relationship between Sara and her human user is the social infrastructure for improved performance.

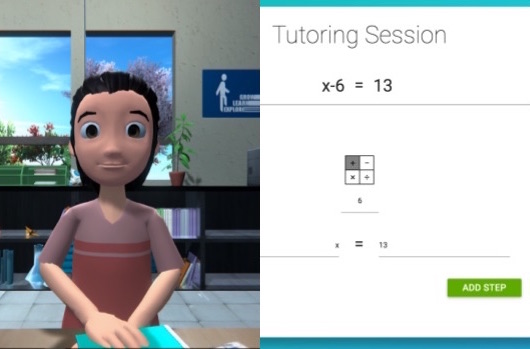
The current application of SARA is the front-end of an event app; that is, a personal assistant that helps conference attendees achieve their goals, including introducing them to other attendees and telling them about sessions that fit their interests. Through rapport-building conversational strategies the agent elicits the user’s interests and preferences and uses these to improve its recommendations. Through estimating the user’s current rate of rapport, and the conversational strategies the user has uttered, the agent is able to choose the right conversational strategies to respond with.
While Sara is a personal assistant for busy conference attendees, applications of our work on socially-aware artificial intelligence have also included educational technologies, such as:
- Culturally-Aligned Virtual Peers: educational technologies in the shape of virtual children that support students in low-resourced schools for whom collaborative learning with peers, and a sense that they belong in their school environment, have been shown to be particularly important to learning gains.
- Authorable Virtual Peers: a system that allows children with high-functioning autism or Aspergers to author behaviors for and control virtual peers as a way to acquire and practice key interactional social skills. Results have demonstrated improved social skills in subsequent peer-peer interaction.
- SCIPR: Educational games that rely on peer dynamics and augmented reality environments to evoke, scaffold, and preserve curiosity in an increasingly “teach-to-the-test” school paradigm.
The Era of the Virtual Personal Assistant
We are living in the era of intelligent personal assistants. Companies large and small are moving forward with the vision of intelligent virtual personal assistants; for example, Apple Siri, Microsoft Cortana, Amazon Alexa and Jibo, and increasingly conversational interaction with these assistants is going to be the norm as the primary way of interacting with these companies’ services. However, while the personability and conversational expertise of these agents is widely touted, they remain primarily search interfaces with a thin veneer of hard-coded sociability.
Our work embodied, literally, in a virtual human on a computer screen, achieves similar functionality as these intelligent personal assistants, but through multimodal interaction (not just language but also body language), and with a focus on building a social relationship with users as the infrastructure to improved effectiveness.
In the current application of SARA as the front end of a conference app, the virtual human engages its users in a conversation to elicit people’s preferences and to recommend to them relevant conference sessions to attend and people to meet. During this process, the system continuously monitors the use of specific conversational strategies (such as self-disclosure, praise, reference to shared experience, etc.) by the human user and uses this knowledge (as well as visual (eye gaze, head nods, and smiles) and vocal (F0 and SMA) behaviors to estimate a level of rapport between the user and system. The system then employs appropriate conversational strategies to raise the level of rapport with the human user, or to maintain the rapport at the same level. The goal is to maintain rapport at a fairly high level, and to use the rapport as a way of eliciting personal information from the user that, in turn, can be used to personalize system responses, and to keep the conversation going. The system’s responses manifest themselves both in Sara’s speech and as her body language.
SARA Technical Innovation
SARA is designed to build interpersonal closeness or rapport over the course of a conversation by managing rapport through the understanding and generation of visual, vocal, and verbal behaviors. The ArticuLab always begins by studying human-human interaction, using that as the basis for our design of artificial intelligence systems. Leveraging our prior work on the dynamics of rapport in human-human conversation this SARA system includes the following components:
- The computational model of rapport: The computational model is the first to explain how humans in dyadic interactions build, maintain, and destroy rapport through the use of specific conversational strategies that function to fulfill specific social goals, and that are instantiated in particular verbal and nonverbal behaviors (Zhao et al., 2014).
- Conversational strategy classification: The conversational strategy classifier can recognize high-level language strategies closely associated with social goals through training on linguistic features associated with those conversational strategies in a test set (Zhao, Sinha, Black and Cassell ( SIGDIAL 2016)).
- Rapport level estimation: The rapport estimator estimates the current rapport level between the user and the agent using temporal association rules cite (Zhao, Sinha, Black and Cassell (IVA 2016 Best Student Paper)).
- Social and task reasoning: The social reasoner outputs a conversational strategy that the system must adopt in the current turn. The reasoner is modeled as the spreading activation network (Cassell et al., under review).
- Natural language and nonverbal behavior generation: The natural language generation module expresses conversational strategies in specific language and associated nonverbal behaviors, and they are performed by a virtual human (Cassell, et al., 2001).
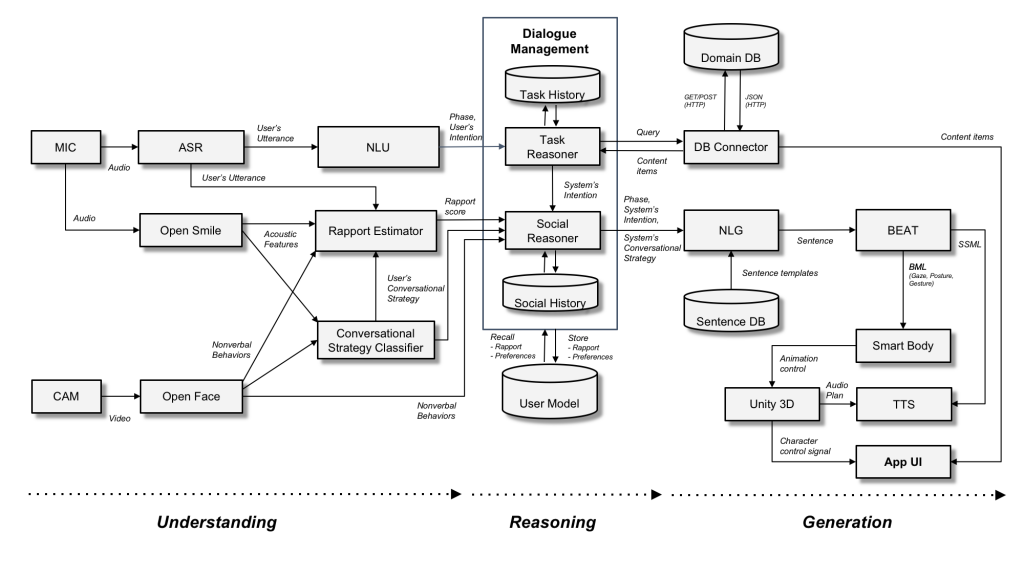
SARA Architecture (Matsuyama, Bhardwaj, Zhao, Romero, Akoju, and Cassell, SIGDIAL 2016)
SARA’s Understanding Process
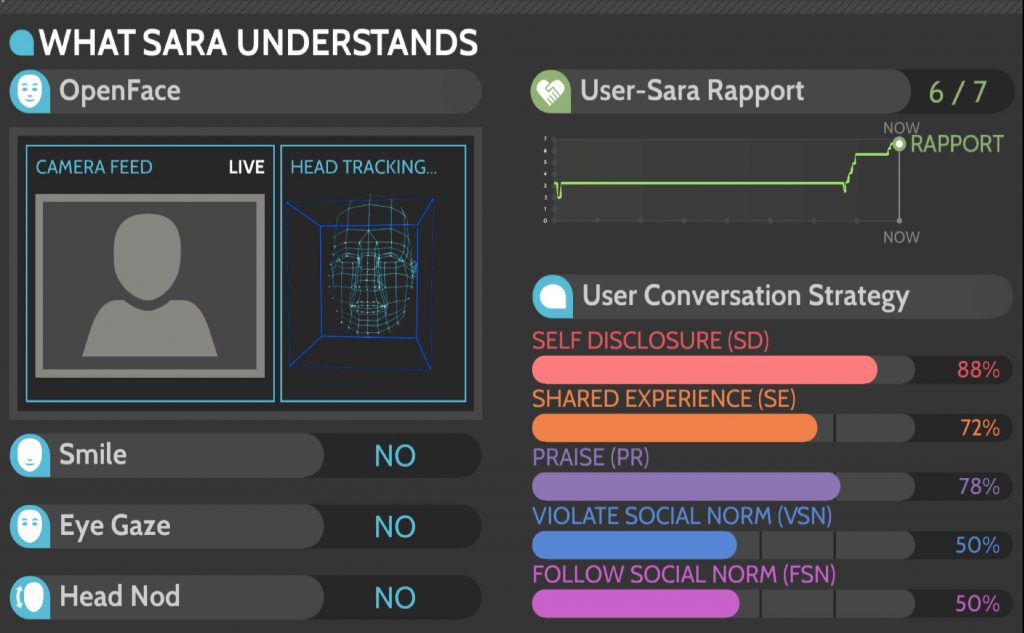
Conversational Strategy Classifier
We have implemented a conversational strategy classifier to automatically recognize the user’s conversational strategies – particular ways of talking, that contribute to building, maintaining or sometimes destroying a budding relationship. These include self-disclosure (SD), elicit self-disclosure (QE), reference to shared experience (RSD), praise (PR), violation of social norms (VSN), and back-channel (BC). By including rich contextual features drawn from verbal, visual and vocal modalities of the speaker and interlocutor in the current and previous turns, we can successfully recognize these dialogue phenomena with an accuracy of over 80% and with a kappa of over 60%
Rapport Estimator
We use the framework of temporal association rule learning to perform a fine-grained investigation into how sequences of interlocutor behaviors signal high and low interpersonal rapport. The behaviors analyzed include visual behaviors such as eye gaze and smiles, and verbal conversational strategies, such as self-disclosure, shared experience, social norm violation, praise and back-channels. We developed a forecasting model involving two-step fusion of learned temporal associated rules. The estimation of rapport comprises two steps: in the first step, the intuition is to learn the weighted contribution (vote) of each temporal association rule in predicting the presence/absence of a certain rapport state (via seven random-forest classifiers); in the second step, the intuition is to learn the weight corresponding to each of the binary classifiers for the rapport states, in order to predict the absolute continuous value of rapport (via linear regression) model. Ground truth for the rapport state was obtained by having naive annotators rate the rapport between two interactants in the teen peer-tutoring corpus for every 30 second slice of an hour long interaction (those slices were randomized in order before being presented to the annotators so that ratings were of rapport states and not rapport deltas).
Reasoning Process

Task Reasoner
Based on the WoZ personal assistant corpus we collected,the task reasoner was designed as a finite state machine whose transitions are governed by an expressive set of rules. The module uses the user’s intention (identified by the NLU), the current state of the dialog (which it maintains) and other contextual information (e.g., how many sessions it has recommended) to transition to a new state, and generate the system intent associated with that state. In order to handle cases where the user takes the initiative, the module allows a set of user intents to cause the system to transition from its current state to a state which can appropriately handle the user’s request. For example, this allows the user to abort the ongoing greeting phase and request the system to suggest a session. In cases where the user’s intent is not in this set, but is also not in the set of expected user intents for the current state, the system relies on a set of fall-back responses (such as “important goals, but not unfortunately ones that I can help you with. However I can recommend a session where seats are going fast, and so it’s probably a good one!”).
Social Reasoner
The social reasoner is designed as a spreading activation model – a behavior network consisting of activation rules that govern which conversation strategy the system should adopt next. Taking as inputs the system’s phase (e.g. “recommendation”) system’s intentions (e.g. “elicit_goals”, “recommend_session”), the history of the user’s conversational strategies, select non-verbal behaviours (e.g. head nod and smile)
and the current rapport level, the activation energies will be updated, the Social Reasoner selects the system’s next conversational strategy, and sends both the system’s intent and conversational strategies to the NLG. The activation pre-conditions of the behavior network are inspired by the analysis carried out on the peer-tutoring corpus and the personal assistant WoZ corpus.
Generation Process
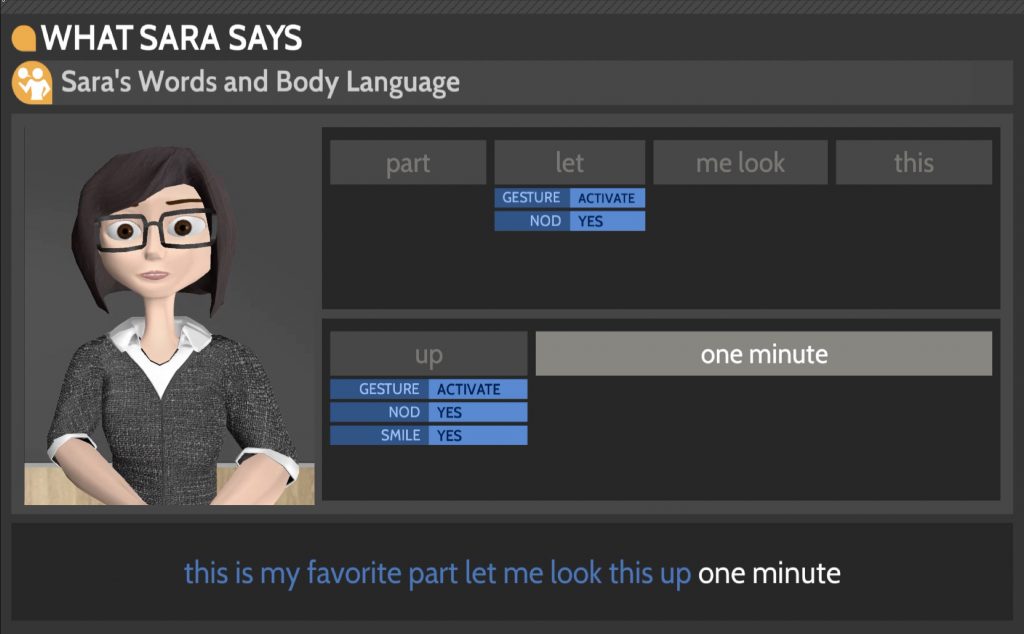
Verbal and Nonverbal Language Generation
Given the system’s intention (which includes the current conversational phase, the system intent, and the conversational strategy) these modules generate sentence and behavior plans. The Natural Language Generator (NLG)
selects a certain syntactic templates associated with the system’s intention from the sentence database. The templates are filled with content items. A generated sentence plan is sent to the BEAT (Behavior Expression Animation Toolkit), a nonverbal generation generator, and BEAT generates a behavior plan in the BML (Behavior Markup Language) form. The BML is then sent to SmartBody, which renders the required non-verbal behaviours on the Embodied Conversation Agent.
Socially-Aware Technologies: The Moral of the Story
The mission of our research is to study human interaction in social and cultural contexts, and use the results to implement computational systems that, in turn, help us to better understand human interaction, and to improve and support human capabilities in areas that really matter. As technologists, and as citizens of the world, it is our choice whether we build killer robots or robots that collaborate with people, our choice whether we seek to obviate the need for social interaction, or ensure that social interaction and interpersonal closeness are as important – and accessible – today as they have always been.

Members
- Principal Investigator
- Justine Cassell
- ArticuLab
- Yoichi Matsuyama
- Ran Zhao
- Arjun Bhardwaj
- Fadi Botros
- David Slebodnick
- Jiajia Li
- Luo Yi Tan
- Summer 2016 Interns: Divya Sai Jitta, Orson Xu, Ting Yan, Ying Shen, Zhao Meng
- Fall 2016 Interns: Akanksha Kartik, Alexander Bainbridge, Anna Tan, Chileshe Otieno, Ethel Chou, Jacqueline Yeung, Sara Stalla, Sasha Volodin
Related Publications
- Zhao, R., Sinha, T., Black, A., & Cassell, J. (2016, September). Socially-Aware Virtual Agents: Automatically Assessing Dyadic Rapport from Temporal Patterns of Behavior, 16th International Conference on Intelligent Virtual Agents (IVA) [*Best Student Paper]
- Zhao, R., Sinha, T., Black, A., & Cassell, J. (2016, September). Automatic Recognition of Conversational Strategies in the Service of a Socially-Aware Dialog System, 17th Annual SIGDIAL Meeting on Discourse and Dialogue
- Matsuyama, M., Bhardwaj, A., Zhao, R., Romero, O., Akoju, S., Cassell, J. (2016, September). Socially-Aware Animated Intelligent Personal Assistant Agent, 17th Annual SIGDIAL Meeting on Discourse and Dialogue
Acknowledgements
SARA (the Socially-Aware Robot Assistant) is a collaboration among Professor Justine Cassell and her research group at Carnegie Mellon University, Oscar Romero and Sushma Ananda from the CMU-Yahoo InMind project, the World Economic Forum, Yahoo Research and Simcoach Games.
Computing Power provided in part by DroneData
SARA benefits from generous funding from a Microsoft faculty research award and a Microsoft equipment donation, a gift from LivePerson, support from the IT R&D program of MSIP/IITP [2017-0-00255, Autonomous digital companion development], and a Google Faculty Award and significant donation of Google Cloud Platform tools.
 |
 |
|
|---|---|---|
 |
Media Coverage
- BBC Business Daily, Talking to Robots
- Foreign Policy, Is AI Sexist?
- CNBC Africa, Meet SARA, the socially-aware robot
- Al Arabiya, Meet Sara…the robot that knows the ins and outs of Davos
- USA TODAY, This robot assistant can understand facial expressions
- MIT Technology Review, Chatbots with Social Skills Will Convince You to Buy Something
- CNET, The Advent of Virtual Humans
- CNBC, Best of World Economic Forum in Tianjin
- CCTV (China Central Television)
- Popular Science, S.A.R.A. Seeks To Give Artificial Intelligence People Skills
- Science Friday, Are Digital Assistants Smart Enough to Do Their Jobs?
- Tartan (Carnegie Mellon’s Student Newspaper) The Frontier Conference exhibits featured new technology
- Radio Sputnik, These are robots that intend to make society stronger by focusing on social bond
- Atelier.net, chatbots of growing human
- Radio Canada, Here are 4 robots at your service
- WASHINGTON POST, The big contradiction in how the world’s most powerful people think about its future
- USA TODAY, This robot assistant can understand facial expressions
- FOREIGN POLICY, Is AI Sexist?
- BLOOMBERG QUINT SARA: A socially aware robotic assistant that reads your mood
- AL ARABIYA, Meet Sara…the robot that knows the ins and outs of Davos
- PressTV, Socially Aware Robot Assistant Displayed at WEF
- INDIA TIMES, Now, a socially-aware robotic assistant that gets your mood!
- THE TRIBUNE, A robotic assistant that gets your mood!
- DAILY NEWS AND ANALYSIS (DNA), Fourth industrial revolution on full display at the WEF
- FINANCIAL TIMES, Tech leaders at Davos fret over effect of AI on jobs
- CNBC AFRICA, Meet SARA, the socially-aware robot
- JLL (Sushell Koul), From macro to machines
- CMSWIRE, Step Up Your Personalization Game with AI
- TECH FACTS LIVE, Socially Aware Robotic Assistant Introduced at World Economic Forum
- ROBOTICS AND AUTOMATION NEWS, Job-stealing robots a growing concern for world leaders
- PTS NEWS NETWORK, Socially-Aware robot frees humans from repetitive work
- DIGITAL MARKETING BUREAU, Sara: The Socially Aware Robot Assistant
- HUMAN INSIDE, S.A.R.A., the sensitive robot who improves people’s performance
- D!GITALIST MAGAZINE, Empathy: The Killer App for Artificial Intelligence
- Zee News, Here’s a socially-aware robotic assistant that gets your mood!
- The Indian Express, Now, a socially-aware robotic assistant (SARA) that gets your mood
- DE TIJD, https://twitter.com/Dorien_Luyckx/status/821731750950871040
- DW – Business, https://twitter.com/dw_business/status/821671699695435776
See Other Projects